1. 背景和目标
1.1 druid版本
- 1.2.3
1.2 背景
- druid作为我们内部通用的数据库连接池,而mysql数据库又是最重要的数据源,我们必须对其充分了解
- 了解druid基本运行原理,对我们在使用他优化他的时候非常有帮助
- 了解druid可能存在的隐患(这可能是个长期的事情,尽量去做)
- 之前发生过shardingsphere和druid配合出问题的案例,现在重新做dal和sharding的starter,对这块要了解清楚
1.3 目标
- 了解真正发生链接时,具体流程
- 了解获取一个链接时,具体流程,如何做池管理
- 了解filter等附加特性的原理及如何定义
- 了解testOnxxx,removeAbandoned等配置的实际意义
- 对其监控的可行性及方案
- HA特性
2. 相对前端/上游说明
2.1 获取连接和使用连接
druid连接池的使用方式是创建一个druidDataSource,所以对于他的调用者都是持有这个DataSource并使用getConnection方法的类。
对于普通的mybatis应用来说,就是mybatis的sql executor 持有druidDataSource,利用他来获取connection。
对于接入mybatis和shardingsphere的应用来说,mybatis调用shardingDataSource的getConnection(shardingDataSource早已经持有druidDataSource),他会再调用druidDataSource。

2.2 回收连接
SQL执行完成之后,无论成功失败,上层代码都会进行 connection.close()
druid通过实现close方法,在其内部逻辑进行了连接的回收。
3. 主体流程分析
3.1 创建dataSource
创建DataSource主要就是创建一个druidDataSource,核心逻辑就是实例化,而执行的时机要看应用的实现。
实例化的时机可能在业务应用,也可能在spring的autoconfigure包,也可能在shardingsphere的shardingDataSource创建的时候。
这里注意一下和mybatis-spring的结合使用,因为他会去找唯一的DataSource,所以要保证DataSource的唯一性。
3.2 DataSource初始化
初始化主流程
init()
初始化流程一般在启动应用时被调起,里面包含4类重要逻辑:
- 各种配置初始化和各种校验
- 初始化后续执行所用到的filter、exceptionSorter、checker
- 创建initialSize的connection
- 启动创建/销毁两个线程
public void init() throws SQLException {
if (inited) {
return;
}
// bug fixed for dead lock, for issue #2980
DruidDriver.getInstance();
final ReentrantLock lock = this.lock;
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
throw new SQLException("interrupt", e);
}
boolean init = false;
try {
if (inited) {
return;
}
// 省略 初始化各种配置
// …………
// …………
initFromSPIServiceLoader();
resolveDriver();
initCheck();
// 初始化exp sorter机制,在mysql场景下会生成MySqlExceptionSorter(见下方分析)
initExceptionSorter();
// 初始化connectionChecker,主要用于testOnXXX,也就是在不同场景下发起简单查询去检查连接是否可用
initValidConnectionChecker();
validationQueryCheck();
// 是否合并多个DruidDataSource的监控数据,跟stat监控相关
if (isUseGlobalDataSourceStat()) {
dataSourceStat = JdbcDataSourceStat.getGlobal();
if (dataSourceStat == null) {
dataSourceStat = new JdbcDataSourceStat("Global", "Global", this.dbTypeName);
JdbcDataSourceStat.setGlobal(dataSourceStat);
}
if (dataSourceStat.getDbType() == null) {
dataSourceStat.setDbType(this.dbTypeName);
}
} else {
dataSourceStat = new JdbcDataSourceStat(this.name, this.jdbcUrl, this.dbTypeName, this.connectProperties);
}
dataSourceStat.setResetStatEnable(this.resetStatEnable);
// 初始化3个holder数组(connections:所有连接,evict:可驱逐的连接,keepAlive:复用的连接)
// 这几个数组主要在shrink销毁线程时起作用。 (见下方DestroyThread分析)
connections = new DruidConnectionHolder[maxActive];
evictConnections = new DruidConnectionHolder[maxActive];
keepAliveConnections = new DruidConnectionHolder[maxActive];
SQLException connectError = null;
// 异步加载,这个跟druid配置有关,如果是异步加载的话,在启动的时候就不会马上同步加载完initial大小的线程池
// 这种方式主要是为了加快启动速度,在我们的场景下不太关心,所以这一部分不做过多分析
if (createScheduler != null && asyncInit) {
for (int i = 0; i < initialSize; ++i) {
submitCreateTask(true);
}
} else if (!asyncInit) {
while (poolingCount < initialSize) {
try {
PhysicalConnectionInfo pyConnectInfo = createPhysicalConnection();
DruidConnectionHolder holder = new DruidConnectionHolder(this, pyConnectInfo);
connections[poolingCount++] = holder;
} catch (SQLException ex) {
LOG.error("init datasource error, url: " + this.getUrl(), ex);
if (initExceptionThrow) {
connectError = ex;
break;
} else {
Thread.sleep(3000);
}
}
}
if (poolingCount > 0) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
}
createAndLogThread();
// 启动创建连接线程,启动销毁连接线程()
createAndStartCreatorThread();
createAndStartDestroyThread();
initedLatch.await();
init = true;
initedTime = new Date();
registerMbean();
if (connectError != null && poolingCount == 0) {
throw connectError;
}
if (keepAlive) {
// async fill to minIdle
if (createScheduler != null) {
for (int i = 0; i < minIdle; ++i) {
submitCreateTask(true);
}
} else {
this.emptySignal();
}
}
} catch (SQLException e) {
//省略
}
}ExceptionSorter
exceptionSorter: https://www.bookstack.cn/read/Druid/452caf873b3a56bf.md
public interface ExceptionSorter {
/**
* Returns true or false whether or not the exception is fatal.
*
* @param e the exception
* @return true or false if the exception is fatal.
*/
boolean isExceptionFatal(SQLException e);
void configFromProperties(Properties properties);
}实际上,无论是mysql还是oracle还是其他数据源,在druid的exceptionSorter里面最重要关注的都是两个方法
1.isExceptionFatal :错误是否致命
这个方法会在prepare、commit、rollback、savepoint… 等各个执行动作遇到异常时被调用,返回true之后,druidDataSource.handleFatalError()会记录错误,然后销毁链接。
具体判断的依据由sorter自己实现。我们主要关注的是MySqlExceptionSorter,可以看到里面是对错误码和错误消息的解析,发现已知的致命异常就返回true(connection在后面就会被销毁)
2.configFromProperties :配置获取
在DataSource初始化的时候允许把配置给到exceptionSorter,也就是赋予exceptionSorter配置化的能力
CreatorThread和DestroyThread
CreatorThread:
当前需要创建connection(connection数未到达maxActive,且有线程在等着用connection),就会触发创建物理连接的流程,并且把connection加入到pool中。
创建connection依靠的是reentranLock的condition唤醒,这种实现和JDK的阻塞队列实现相似,此处不做细节分析。
DestroyThread:
实际上调用shrink方法。在shrink的时候,会遍历connections数组,把需要驱逐的连接evictConnections和复用连接keepAliveConnections都移除然后放进另外两个数组,然后把keepAlive的连接检查正常的再放回原数组。
shrink这里不再做细节分析,主要就是上述计数器和数组的处理。代码的具体分析可以看 https://cloud.tencent.com/developer/article/1901410
3.3 获取连接
获取连接主流程
getConnectionInternal(long maxWait)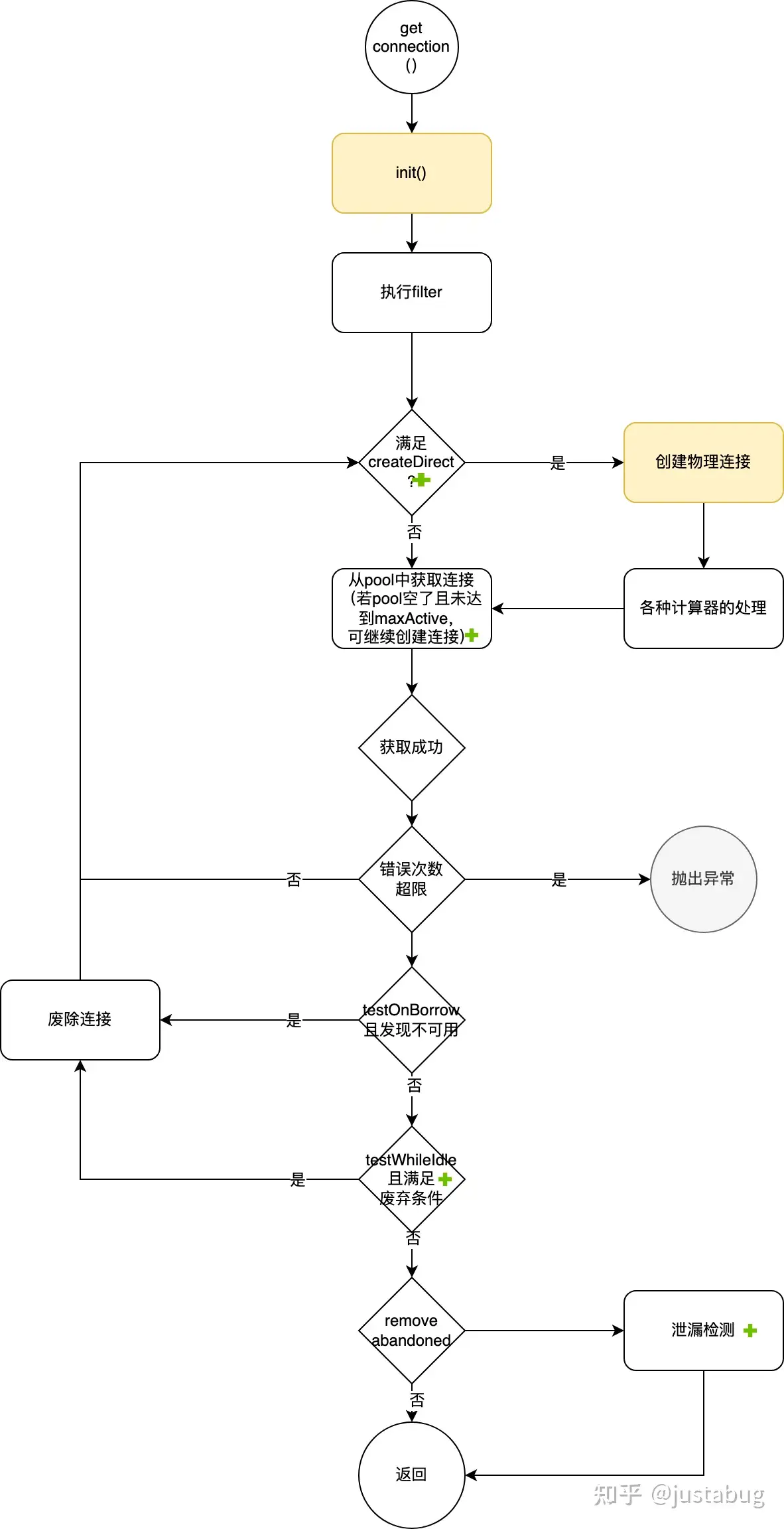
获取连接最核心的动作是从pool中获取,但如果是异步加载的话会有些不同。
createDirect
是否直接创建连接,该版本的写法是用死循环来判断连接是否已经获取成功,获取到的连接是否可用,如果可用的话就返回连接,否则回到循环开始执行create。
创建成功后会立刻判断是否超过最大active,超过的话会销毁该连接。
getConnectionInternal() 片段
if (activeCount < maxActive) {
activeCount++;
holder.active = true;
if (activeCount > activePeak) {
activePeak = activeCount;
activePeakTime = System.currentTimeMillis();
}
break;
} else {
discard = true;
}testOnBorrow(获取监测)
获取连接时执行validationQuery检测连接是否有效。
(检测逻辑就是执行validationQuery)开启后每次获取连接都会进行查询,对性能影响非常大。
testWhileIdle(闲置监测)
如果连接空闲时间大于timeBetweenEvictionRunsMillis指定的毫秒,就会执行参数validationQuery指定的SQL来检测连接是否有效。
判断空闲时间后再执行检查,实际上对性能影响不大。而且提前检测可能失效掉的连接,实际上有助于突发大量SQL的性能提升。
removeAbandoned(连接泄漏监测)
if (removeAbandoned) {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
poolableConnection.connectStackTrace = stackTrace;
poolableConnection.setConnectedTimeNano();
poolableConnection.traceEnable = true;
....
....收集堆栈信息,对性能有影响,这个只能用在怀疑泄漏时的验证
创建物理连接

流程比较简单,这里不做源码展示
3.4 关闭连接(回收连接)
执行sql完成之后,查询组件会对connection进行关闭,进入connection的close()方法
这个connection实际上是DruidPooledConnection,下面是这个类的close流程
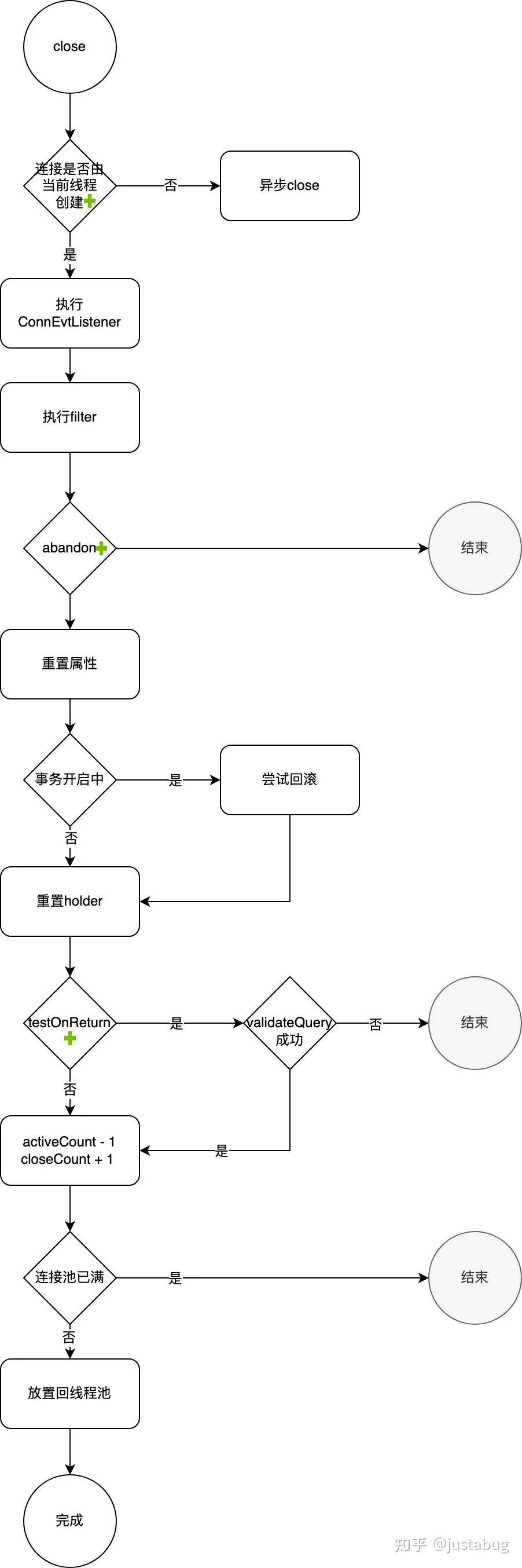
filter执行
同样是基于druid的filter机制,可以创建filter加入到recycle过程,需要实现dataSource_releaseConnection方法
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(dataSource);
filterChain.dataSource_recycle(this);
}abandon/recycle
连接是否已经不可用,在removeAbandoned逻辑中可能会把连接给禁用。如果没有禁用则进入DruidDataSource的recycle方法
if (!this.abandoned) {
DruidAbstractDataSource dataSource = holder.getDataSource();
dataSource.recycle(this);
}回滚处理
try {
// check need to rollback?
if ((!isAutoCommit) && (!isReadOnly)) {
pooledConnection.rollback();
}testOnReturn(回收监测)
归还连接时执行validationQuery检测连接是否有效。
(检测逻辑就是执行validationQuery)开启后每次回收连接都会进行查询,对性能影响非常大。
4. 设计赏析
4.1 关键类型结构设计

| Class | 与其他类或接口的关系 | 说明 |
|---|---|---|
| DruidDataSource | extends DruidAbstractDataSourceimplements DruidDataSourceMBean, ManagedDataSource, Referenceable, Closeable, Cloneable, ConnectionPoolDataSource, MBeanRegistration | 数据源连接核心参数和物理连接核心处理 |
| DruidPooledConnection | extends PoolableWrapperimplements javax.sql.PooledConnection, Connection | 连接池化管理模型的实现 |
| DruidConnectionHolder | 持有DataSource和connection | 主要是持有当前所有数据源和连接,方便随时获取 |
| FilterChain | 管理所有的Filter | 串联起所有filter |
| Filter | 由FilterChain调用 | 允许用户在多达20个环境进行拦截处理 |
4.2 扩展机制和可监控性
druid线程池在设计之初就预留了观测点和检验机制,从上面的流程图也可以看出,各个环节都有扩展点,允许应用程序去做扩展。
druid也内置了几个常用的filter,用于观察连接的动作。另外druid还自带了监控界面,可以直接查看监控数据。
除了监控,druid还实现了trace和泄漏排查,在数据库出问题时排查能力也是优于其他线程池很多。
4.3 其他机制
exceptionSorter
当网络断开或者数据库服务器Crash时,连接池里面会存在“不可用连接”,连接池需要一种机制剔除这些“不可用连接”。在Druid和JBoss连接池中,剔除“不可用连接”的机制称为ExceptionSorter,实现的原理是根据异常类型/Code/Reason/Message来识别“不可用连接”。没有类似ExceptionSorter的连接池,在数据库重启或者网络中断之后,不能恢复工作,所以ExceptionSorter是连接池是否稳定的重要标志。
5. 总结
5.1 目标达成
- 了解真正发生链接时,具体流程:
- 参考上面的“创建物理连接”。
- 了解获取一个链接时,具体流程,如何做池管理:
- 参考上面的“获取连接”。
- 了解filter等附加特性的原理及如何定义:
- 了解了filter,并在BCF中实现了结合CAT的druid filter。
- 了解testOnxxx,removeAbandoned等配置的实际意义:
- 上述分析内容中已列举,目前看来只需要开启testWhileIdle,其他的都建议不开启。
- 对其监控的可行性及方案:
- 创建filter用于监控。
- HA特性:
- 暂未了解
Comments are closed, but trackbacks and pingbacks are open.